1
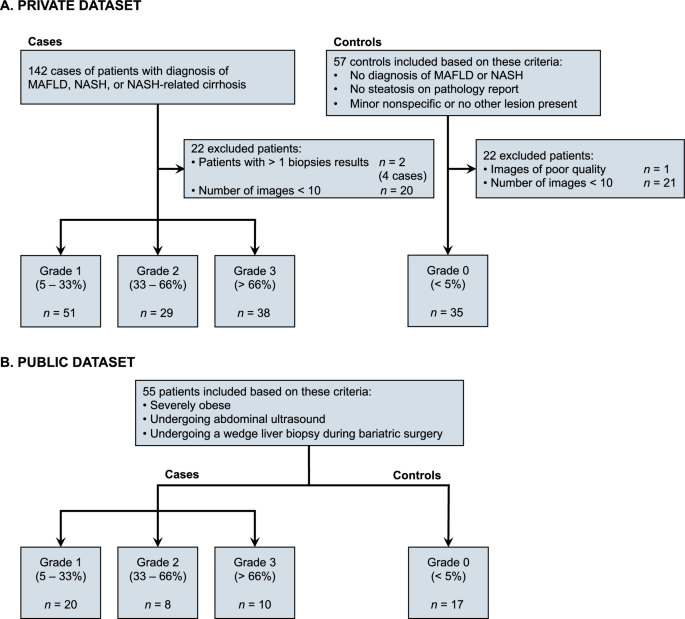
We aimed to implement four data partitioning strategies evaluated with four federated learning (FL) algorithms and investigate the impact of data distribution on FL model performance in detecting steatosis using B-mode US images. A private dataset (153 patients; 1530 images) and a public dataset (55 patient; 550 images) were included in this retrospective study. The datasets contained patients with metabolic dysfunction-associated fatty liver disease (MAFLD) with biopsy-proven steatosis grades and control individuals without steatosis. We employed four data partitioning strategies to simulate FL scenarios and we assessed four FL algorithms. We investigated the impact of class imbalance and the mismatch between the global and local data distributions on the learning outcome. Classification performance was assessed with area under the receiver operating characteristic curve (AUC) on a separate test set. AUCs were 0.93 (95% CI 0.92, 0.94) for source-based partitioning scenario with FedAvg, 0.90 (95% CI 0.89, 0.91) for a centralized model, and 0.83 (95% CI 0.81, 0.85) for a model trained in a single-center scenario. When data was perfectly balanced on the global level and each site had an identical data distribution, the model yielded an AUC of 0.90 (95% CI 0.88, 0.92). When each site contained data exclusively from one single class, irrespective of the global data distribution, the AUC fell in the range of 0.34–0.70. FL applied to B-mode US images provide performance comparable to a centralized model and higher than single-center scenario. Global data imbalance and local data heterogeneity influenced the learning outcome.
You must log in or register to comment.